
Cool stuff
Bread Percentages Calculation
Here, you can calculate percentages for sourdough bread baking and play with weights and percentages.
contents: text
hw requirements: none
os: os independent
This is a re-traced vector form of the Evo X engine bay fuse boxes. Useful if you are replacing them for the carbon fiber ones and want to retain the graphics.
contents: PDF text
hw requirements: none
os: os independent
This is an electronic copy of my Ph.D. thesis ("Accelerated Sparse Matrix Operations in Nonlinear Least Squares Solvers", 2016, Brno University of Technology). Abstract:
This thesis focuses on data structures for sparse block matrices and the associated algorithms for performing linear algebra operations that I have developed. Sparse block matrices occur naturally in many key problems, such as Nonlinear Least Squares (NLS) on graphical models. NLS are used by e.g. Simultaneous Localization and Mapping (SLAM) in robotics, Bundle Adjustment (BA) or Structure from Motion (SfM) in computer vision. Sparse block matrices also occur when solving Finite Element Methods (FEMs) or Partial Differential Equations (PDEs) in physics simulations.
The majority of the existing state of the art sparse linear algebra implementations use elementwise sparse matrices and only a small fraction of them support sparse block matrices. This is perhaps due to the complexity of sparse block formats which reduces computational efficiency, unless the blocks are very large. Some of the more specialized solvers in robotics and computer vision use sparse block matrices internally to reduce sparse matrix assembly costs, but finally end up converting such representation to an elementwise sparse matrix for the linear solver.
Most of the existing sparse block matrix implementations focus only on a single operation, such as the matrix-vector product. The solution proposed in this thesis covers a broad range of functions: it includes efficient sparse block matrix assembly, matrix-vector and matrix-matrix products as well as triangular solving and Cholesky factorization. These operations can be used to construct both direct and iterative solvers as well as to compute eigenvalues. Highly efficient algorithms for both Central Processing Units (CPUs) and Graphics Processing Units (GPUs) are provided.
The proposed solution is integrated in SLAM++, a nonlinear least squares solver focused on robotics and computer vision. It is evaluated on standard datasets where it proves to significantly outperform other similar state of the art implementations, without sacrificing generality or accuracy in any way.
contents: PDF text
hw requirements: none
os: os independent
Math reading seminar on Bundle Adjusmtent
These are slides for my talk on Bundle Adjustment and all things related that ran 10th, 17th and 24th Feb 2017 at Brno University of Technology. It covers the basics of 3D and projective geometry, minimal geometric problems, least squares, computing derivatives, robust methods, solving linear systems and calculating covariances. There's also a PDF version available. Furthermore, there are some Matlab demos.
contents: PowerPoint slides
hw requirements: none
os: os independent
Classic Feces
Classic Feces is a Ph.D. thesis template for LaTeX, derived from Classic Thesis. It is more ready to be used out-of-the-box and fixes a plethora of issues (more details are in the template text). It also conforms to the Brno University of Technology Requirements.
Additionally, this contains build rules for multiple bibliographies (the main bibliography and author's own publications) and scripts for efficient building on Linux (OS X) and on Windows.
contents: tex source codes, compiled pdf
hw requirements: none
os: os independent
Expand OpenCL includes
If you spent any time writing OpenCL kernels, you probably noticed that it is possible
to #include files. While this is a reasonably good way to reduce repeated
code, it also makes it harder to package your application. This utility partially
preprocesses your kernel files and expands the includes. It also (optionally) adds the
#line directives so that if there are compile errors, the line numbers
and the original source file name are reported correctly.
This also includes a build rule for Visual Studio 2008 (the newer versions have redesigned build rules so unfortunately someone will need to create a new rule file for those newer versions). This build rule cooperates with File-to-header to package the kernel in an include file so that it is not needed to package the kernel files alongside your application. Note that the kernels should be built in a separate VS project on which your main project should depend, to ensure correct build order (otherwise the headers get updated and the depending C++ files that include them may not get compiled anymore).
contents: source codes, win32 executable
hw requirements: none
os: win32
mktemp for Windows
This is a simple script which gets unique temporary file name on Windows. It creates the
file in the process to guarantee that it stays unique. It uses the mkdir
command as a mutex so it is thread safe (multiple threads executing concurrently are
guaranteed to always get different files).
contents: win32 bash script
hw requirements: none
os: win32
How to draw a box
There is a few ways of representing a cube. When drawing without texture coordinates, it turns out that a cube can be drawn as a single triangle strip. Might come in handy for rendering skyboxes (although that can be done with a single triangle and a fragment shader nowadays) or for rendering some simple debris:
const float p_box_vertices[] = {
-1, -1, -1, // 7-------6
+1, -1, -1, // /| /|
+1, -1, +1, // / | / | y+
-1, -1, +1, // 4-------5 | ^ z+
-1, +1, -1, // | 3----|--2 |/
+1, +1, -1, // | / | / +-> x+
+1, +1, +1, // |/ |/
-1, +1, +1, // 0-------1
};
const unsigned short p_box_indices[] = {
//1, 0, 2, 3, 7, 0, 4, 1, 5, 2, 6, 7, 5, 4 // CCW triangle strip
0, 1, 3, 2, 6, 1, 5, 0, 4, 3, 7, 6, 4, 5 // CW triangle strip
};
// CCW / inwards-looking | CW / outwards-looking
// |
// 4---5 | 4---5
// | /| | |\ |
// |/ | | | \|
// 7---6---5---4---7 | 6---5---4---7---6
// \ | /| /| /|\ | /|\ |\ |\ | /
// \|/ |/ |/ | \ | / | \| \| \|/
// 2---1---0---3---2 | 3---2---1---0---3
// | /| | |\ |
// |/ | | | \|
// 0---1 | 0---1
You don't really need additional coords for shading, since this is a unit box the positions can also double as normals. Note that if texture coordinates are desired and texture wrap is an option, the texture coordinates can be assigned in the same plane as the drawing above and one can draw a whole textured box as a single triangle strip using 14 vertices (no vertex repeats, the index array becomes unnecessary).
When texture coordinates are required but texture wrap is not wanted (e.g. if the texture to be applied is a part of a texture atlas), the options get interesting. If you don't mind the texture being rotated or mirrored, you can get down to 12 vertices per box:
const float p_box_vertices[12 * 5] = { // interleaved as 2 texture coords, 3 position
0, 0, -1, -1, 1, 0, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 0, -1, 1, 1,
0, 1, -1, -1, -1, 0, 0, -1, 1, -1, 1, 0, 1, 1, -1, 1, 1, 1, -1, -1,
0, 1, -1, 1, 1, 1, 0, 1, -1, 1, 0, 0, 1, 1, 1, 1, 1, -1, -1, 1
};
const unsigned short p_box_indices[36] = { // triangles
0, 1, 2, 0, 2, 3,
4, 5, 6, 4, 6, 7,
5, 8, 2, 5, 2, 6,
4, 7, 9, 4, 9, 0,
7, 6, 10, 7, 10, 1,
4, 11, 3, 4, 3, 5
};
Where mirrored textures would be disturbing (e.g. when doing normal mapping, the tangent spaces would have two different polarities and that would further complicate stuff), two extra vertices are needed:
const float p_box_vertices[14 * 5] = { // interleaved as 2 texture coords, 3 position
0, 0, -1, -1, 1, 0, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 0, -1, 1, 1,
0, 1, -1, -1, -1, 1, 1, -1, 1, -1, 1, 0, 1, 1, -1, 0, 0, 1, -1, -1,
0, 0, -1, 1, -1, 0, 1, -1, 1, 1, 1, 1, 1, -1, -1, 1, 0, 1, -1, 1,
0, 0, 1, 1, 1, 1, 1, -1, -1, 1
};
const unsigned short p_box_indices[36] = { // triangles
0, 1, 2, 0, 2, 3,
4, 5, 6, 4, 6, 7,
8, 9, 2, 8, 2, 6,
4, 10, 11, 4, 11, 0,
10, 6, 12, 10, 12, 1,
4, 13, 3, 4, 3, 8
};
Finally, where turning the texture would be disturbing (e.g. when displaying text on the cube), 20 vertices are needed:
const float p_box_vertices[20 * 5] = { // interleaved as 2 texture coords, 3 position
0, 1, -1, -1, 1, 1, 1, 1, -1, 1, 1, 0, 1, 1, 1, 0, 0, -1, 1, 1,
1, 1, -1, -1, -1, 1, 0, -1, 1, -1, 0, 0, 1, 1, -1, 0, 1, 1, -1, -1,
0, 0, -1, 1, -1, 0, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, -1,
0, 1, -1, -1, -1, 1, 1, 1, -1, -1, 1, 0, 1, -1, 1, 0, 0, -1, -1, 1,
0, 0, 1, 1, 1, 0, 1, 1, -1, 1, 1, 1, -1, -1, 1, 1, 0, -1, 1, 1
};
const unsigned short p_box_indices[36] = { // triangles
0, 1, 2, 0, 2, 3,
4, 5, 6, 4, 6, 7,
8, 9, 10, 8, 10, 11,
12, 13, 14, 12, 14, 15,
13, 11, 16, 13, 16, 17,
12, 18, 19, 12, 19, 8
};
In case using texture repeat and coordinates with values more than 1 is fine, it is possible to bring those 20 vertices down to 14:
const float p_box_vertices[14 * 5] = { // interleaved as 2 texture coords, 3 position
0, 2, -1, -1, 1, 1, 2, 1, -1, 1, 1, 1, 1, 1, 1, 0, 1, -1, 1, 1,
3, 2, -1, -1, -1, 3, 1, -1, 1, -1, 2, 1, 1, 1, -1, 2, 2, 1, -1, -1,
0, 0, -1, 1, -1, 1, 0, 1, 1, -1, 0, 3, -1, -1, -1, 1, 3, 1, -1, -1,
4, 2, -1, -1, 1, 4, 1, -1, 1, 1
};
const unsigned short p_box_indices[36] = { // triangles
0, 1, 2, 0, 2, 3,
4, 5, 6, 4, 6, 7,
8, 3, 2, 8, 2, 9,
10, 11, 1, 10, 1, 0,
7, 6, 2, 7, 2, 1,
4, 12, 13, 4, 13, 5
};
These arrays were generated by exhaustively trying all the combinations for a couple of weeks on an 8 core CPU. If you want the code, drop me a line and I can make it public.
contents: text/"C"
hw requirements: none
os: os independent
Visual Studio Build Scheduler
Have you discovered the beauty of the /MP switch in Visual Studio? If not, it enables parallel builds, btw. The only impleasant issue is that the parallel builds may be demanding and render the computer irresponsive and sluggish. While it is possible to use less CPU cores for the builds, it seems like a waste ... and there is a better solution.
This is a simple Windows service, which monitors CPU usage (once every five seconds). If the usage gets above 95%, it starts looking for cl.exe processes, and assigns full processor afinity and below normal priority for all the instances it finds.
That way the parallel builds do not eat all the resources, and on the other hand less demanding builds run unaffected, at full speed as before. The source code is very simple, all kinds of modifications are possible. To install, simply run "BuildScheduler_RegisterService.bat" (you may need administrator rights for that) and then you can start it in control panel / services, under "Visual Studio Build Monitor Service". It will also start automatically after the next boot.
contents: source code and win32 executable
hw requirements: none
os: win32, all versions of Visual Studio that use cl.exe (all so far)
HTTP Latch
This is a minimal remote control program. To use it, you specify a secret password and a port to listen at. Then it runs a minimal HTTP server and shows a small form at the specified port where the password can be entered remotely. Once a correct password is entered, it terminates itself.
Coincidentially, it is very safe as it does not at all access filesystem, and it does not have capability to execute any commands on itself. The password is sent using double salted hash.
So what is it good for? It can serve as the proverbial deadbolt for any scripting. By starting the app from a script, it blocks execution of that script, until someone enters password remotely, and then the script can continue. Very simple, quite powerful.
One of the popular uses is restarting remote access application once it hungs (the script contains a simple infinite loop with the latch, kill app and start app command - that way everytime a correct password is entered, the remote access app is restarted).
ÜberLame framework r22 is necessary to compile this, the newest version can be found in projects section.
contents: source code and win32 executable
hw requirements: none
os: win32, linux
File-to-header utility 2.03
File to header is a small command-line utility, created for purpose of storing text or binary files in source code form (that is useful for e.g. packing OpenGL shaders or OpenCL kernels to your app). It reads the input file and stores it as a C++ class.
Text files are stored in plain-text form so they are fairly readable in the packed form as well. For easier orientation, line numbers can be optionally annotated using comments. Options to convert newlines or strip comments serve to reduce payload size while maintaining the same level of readability (specifically, the comments are removed from the string, but are present in the generated file).
Binary files are compressed using a simple BWT compressor, followed by MTF-1, RLE and a Huffman coder. The output is stored as a BASE-85 C++ string. Some compilers have problems with strings, longer than 64 kB, so the string is automatically split to smaller segments. The compression ratios are reasonable, about 1:2 for common text files, or more for highly structured xml. The decompression routine is quite simple, and in case your application includes more files, it can be shared among them.
contents: source code and win32 executable, linux makefile
hw requirements: none
os: win32, linux
Bit twiddles for OpenCL
Some simple bit hacks for OpenCL kernels, running on GPU. Works both compile time and runtime.
// === bit twiddles for OpenCL ===
/**
* @brief sums even and odd bits in a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns a number with bit pairs, containing sums
* of ones in the same corresponding bits in the original number.
*/
#define n_Sum_EvenOddBits(x) ((x) - (((x) >> 1) & 0x55555555U))
/**
* @brief sums bit pairs in a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns a number with nibbles, each containing a sum
* of values of two corresponding bit pairs in the original number.
*/
#define n_Sum_BitPairs(x) (((x) & 0x33333333U) + (((x) >> 2) & 0x33333333U))
/**
* @brief sums bit nubbles in a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns a number with each byte containing a sum
* of values of its two nibbles in the original number.
*/
#define n_Sum_Nibbles(x) (((x) + ((x) >> 4)) & 0x0f0f0f0f)
/**
* @brief sums values of bytes a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns a sum of values of the four bytes of the original number.
*/
#define n_Sum_Bytes(x) (((x) * 0x01010101) >> 24)
/**
* @brief counts set bits in a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns number of bits that are set.
*/
#define n_SetBit_Num(x) n_Sum_Bytes(n_Sum_Nibbles(n_Sum_BitPairs(n_Sum_EvenOddBits(x))))
/**
* @brief determines whether a number is power of two, or not, can be evaluated at compile-time
* @param[in] n_x is number being tested. note it must be positive
* @return Returns true if n_x is power of two, otherwise returns false.
*/
#define b_Is_POT(n_x) (!((n_x) & ((n_x) - 1)))
/**
* @brief set all bits after the first leading bit in each nibble
* @param[in] x is 32-bit integer constant
* @return Returns the number with the set bits duplicated
* towards LSB in each nibble of the input.
*/
#define n_RightFill_4(x) ((x) | ((x) >> 1) | (((x) | ((x) >> 1)) >> 2))
/**
* @brief set all bits after the first leading bit in each byte
* @param[in] x is 32-bit integer constant
* @return Returns the number with the set bits duplicated
* towards LSB in each byte of the input.
*/
#define n_RightFill_8(x) (n_RightFill_4(x) | (n_RightFill_4(x) >> 4))
/**
* @brief set all bits after the first leading bit in each short
* @param[in] x is 32-bit integer constant
* @return Returns the number with the set bits duplicated
* towards LSB in each short of the input.
*/
#define n_RightFill_16(x) (n_RightFill_8(x) | (n_RightFill_8(x) >> 8))
/**
* @brief set all bits after the first leading bit in the input
* @param[in] x is 32-bit integer constant
* @return Returns the input number with the set bits duplicated towards LSB.
*/
#define n_RightFill_Int(x) (n_RightFill_16(x) | (n_RightFill_16(x) >> 16))
/**
* @brief calculates power of two greater or equal to the argument
*
* @param[in] x is 32-bit integer constant
*
* @return Returns power of two greater or equal to the input.
*
* @note In case _Ty is unsigned and n_x is greater than the largest power of two,
* representable by the given type, returns null.
* @note In case _Ty is signed and n_x is greater than the largest power of two,
* representable by this type, returns the maximum negative value representable
* by this type (can be set to zero by masking-out the sign bit).
*/
#define n_Make_POT(x) (n_RightFill_Int((x) - 1) + 1)
/**
* @brief calculates power of two lower or equal to the argument
* @param[in] x is 32-bit integer constant
* @return Returns power of two lower or equal to the input.
*/
#define n_Make_Lower_POT(x) (n_RightFill_Int((x) >> 1) + 1)
/**
* @brief calculates base-2 logarithm (round down)
* @param[in] x is 32-bit integer constant
* @return Returns base-2 logarithm of the input.
*/
#define n_Log2(x) n_SetBit_Num(n_Make_Lower_POT(x) - 1)
// === ~bit twiddles for OpenCL ===
Or with less comments:
// === bit twiddles for OpenCL ===
#define n_Sum_EvenOddBits(x) ((x) - (((x) >> 1) & 0x55555555U))
#define n_Sum_BitPairs(x) (((x) & 0x33333333U) + (((x) >> 2) & 0x33333333U))
#define n_Sum_Nibbles(x) (((x) + ((x) >> 4)) & 0x0f0f0f0f)
#define n_Sum_Bytes(x) (((x) * 0x01010101) >> 24)
#define n_RightFill_4(x) ((x) | ((x) >> 1) | (((x) | ((x) >> 1)) >> 2))
#define n_RightFill_8(x) (n_RightFill_4(x) | (n_RightFill_4(x) >> 4))
#define n_RightFill_16(x) (n_RightFill_8(x) | (n_RightFill_8(x) >> 8))
#define n_RightFill_Int(x) (n_RightFill_16(x) | (n_RightFill_16(x) >> 16))
/**
* @brief counts set bits in a 32-bit integer constant
* @param[in] x is 32-bit integer constant
* @return Returns number of bits that are set.
*/
#define n_SetBit_Num(x) n_Sum_Bytes(n_Sum_Nibbles(n_Sum_BitPairs(n_Sum_EvenOddBits(x))))
/**
* @brief determines whether a number is power of two, or not, can be evaluated at compile-time
* @param[in] n_x is number being tested. note it must be positive
* @return Returns true if n_x is power of two, otherwise returns false.
*/
#define b_Is_POT(n_x) (!((n_x) & ((n_x) - 1)))
/**
* @brief calculates power of two greater or equal to the argument
*
* @param[in] x is 32-bit integer constant
*
* @return Returns power of two greater or equal to the input.
*
* @note In case _Ty is unsigned and n_x is greater than the largest power of two,
* representable by the given type, returns null.
* @note In case _Ty is signed and n_x is greater than the largest power of two,
* representable by this type, returns the maximum negative value representable
* by this type (can be set to zero by masking-out the sign bit).
*/
#define n_Make_POT(x) (n_RightFill_Int((x) - 1) + 1)
/**
* @brief calculates power of two lower or equal to the argument
* @param[in] x is 32-bit integer constant
* @return Returns power of two lower or equal to the input.
*/
#define n_Make_Lower_POT(x) (n_RightFill_Int((x) >> 1) + 1)
/**
* @brief calculates base-2 logarithm (round down)
* @param[in] x is 32-bit integer constant
* @return Returns base-2 logarithm of the input.
*/
#define n_Log2(x) n_SetBit_Num(n_Make_Lower_POT(x) - 1)
// === ~bit twiddles for OpenCL ===Or with no comments at all:
// === bit twiddles for OpenCL ===
#define n_Sum_EvenOddBits(x) ((x) - (((x) >> 1) & 0x55555555U))
#define n_Sum_BitPairs(x) (((x) & 0x33333333U) + (((x) >> 2) & 0x33333333U))
#define n_Sum_Nibbles(x) (((x) + ((x) >> 4)) & 0x0f0f0f0f)
#define n_Sum_Bytes(x) (((x) * 0x01010101) >> 24)
#define n_RightFill_4(x) ((x) | ((x) >> 1) | (((x) | ((x) >> 1)) >> 2))
#define n_RightFill_8(x) (n_RightFill_4(x) | (n_RightFill_4(x) >> 4))
#define n_RightFill_16(x) (n_RightFill_8(x) | (n_RightFill_8(x) >> 8))
#define n_RightFill_Int(x) (n_RightFill_16(x) | (n_RightFill_16(x) >> 16))
#define n_SetBit_Num(x) n_Sum_Bytes(n_Sum_Nibbles(n_Sum_BitPairs(n_Sum_EvenOddBits(x))))
#define b_Is_POT(n_x) (!((n_x) & ((n_x) - 1)))
#define n_Make_POT(x) (n_RightFill_Int((x) - 1) + 1)
#define n_Make_Lower_POT(x) (n_RightFill_Int((x) >> 1) + 1)
#define n_Log2(x) n_SetBit_Num(n_Make_Lower_POT(x) - 1)
// === ~bit twiddles for OpenCL ===
contents: text/"C"
hw requirements: OpenCL capable GPUs or CPUs
os: os independent
Sparse matrix multiplication
Interactive sparse matrix multiplication, if you forgot how it works (happens to me all the time).
contents: text/javascript
hw requirements: none
os: os independent
Image-to-header utility 3.2
Image to header is small command-line utility, created for purpose of converting images to source code form. It reads image in jpeg / png / tga format, may do some image processing (currently only grayscale conversion is available) and stores the image as a C++ class.
This uses somewhat more ealborate (lossy or lossless) compression scheme, than its predecessor. It works in YCbCr(A) color space (or grayscale (alpha)) and allows chromacity planes subsampling, similar to JPEG. It also allows storing chromacity with less than 8 bits per pixel (kind of "quantisation"). Then, there's the prediction step, using one of many predictors, not unlike PNG does. Finally, there's a RLE step, followed by a Huffman coder. The output is stored as a BASE85 C++ string. Some compilers have problems with strings, longer than 64 kB, so the string is automatically split to smaller segments.
While this may seem quite complicated, decoding takes just under 200 lines of neat plain C++ (without any crazy macros, obfuscation or whatever someone may think of to make the code shorter). Compression ratios about 5:1 can be achieved in lossy mode, and 3:1 in lossless mode. It's not very impressive, but sufficient (given simplicity of the decompressor code). Also note, that the final BASE85 step expands the data in 4:5 ratio. In case your application includes more files, the decompressor routine can be shared among them.
The only aim is to avoid including some additional files for projects that just need to display a small logo, etc ...
contents: source code and win32 executable
hw requirements: none
os: win32, should be compilable under linux as well
std::lower_bound() and std::upper_bound()
Do you always get confused about the supposed behavior of the std::lower_bound() and std::upper_bound() functions? I do, and that's why I've written this short piece of code to demonstrate what it does:
{0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 5, 5, 5}
^ // lower_bound(-1)
^ // lower_bound(0)
^ // lower_bound(1)
^ // lower_bound(2)
^ // lower_bound(3)
^ // lower_bound(4)
^ // lower_bound(5)
^ // lower_bound(6)
{0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 5, 5, 5}
^ // upper_bound(-1)
^ // upper_bound(0)
^ // upper_bound(1)
^ // upper_bound(2)
^ // upper_bound(3)
^ // upper_bound(4)
^ // upper_bound(5)
^ // upper_bound(6)
Press any key to continue
So, basically, you use std::lower_bound() if you want to find an element in sorted array, or if you want to insert an element. You use upper_bound() if you want to insert an element after an element with the given key. You use both to get range of occurences of the same value (or range of values).
contents: source code
hw requirements: none
os: os independent
Advisory on setting your volume right
Ever wondered about how soundcards implement volume control? A nice way to do it is to control the voltage coming in the D/A converters, so that the signal itself would not need to be modified. There are some peculiarities to the process, as the transistors only have certain threshold below which they don't work, and then there's the nonlinearities involved. This is the way the nice expensive soundcards (should) do it.
The other way to do it is to use multiplication. It's a simple modification of the signal, but the point is that with more attenuation, more bits is zero, and the signal is represented by less bits, hence losing dynamic range. So when the volume is really low, the signal might be represented by just a single bit, and the signal-to-noise ratio is only about 6.02 dB.
And what is this all about then? Some cards allow the setting of volume in integer decibels. The formula to calculate scaling factor from decibels is: factor = exp(.1 * atten_dB). The engineering wisdom is that the every -6dB is half of the volume down. But it's only approximation, as illustrated in the following table:
| volume | factor |
|---|---|
| 0 dB | 1.000 |
| -1 dB | 0.904 |
| -2 dB | 0.818 |
| -3 dB | 0.740 |
| -4 dB | 0.670 |
| -5 dB | 0.606 |
| -6 dB | 0.548 |
| -7 dB | 0.496 |
| -8 dB | 0.449 |
| -9 dB | 0.406 |
| -10 dB | 0.367 |
| -11 dB | 0.332 |
| -12 dB | 0.301 |
As you can see, the scaling factors are not very even, the number of bits lost is not integer, and the resulting noise is not strictly increasing, there can be some settings that produce less noise than the others. To prove this, a small program was written, which generates a 10 seconds of modulated frequency sweep signal (in double precission floating point), calculates the quantization error (to prove that the numbers are approximately correct), and then calculates noise at each of the volume setting. You can see the result on the following image:
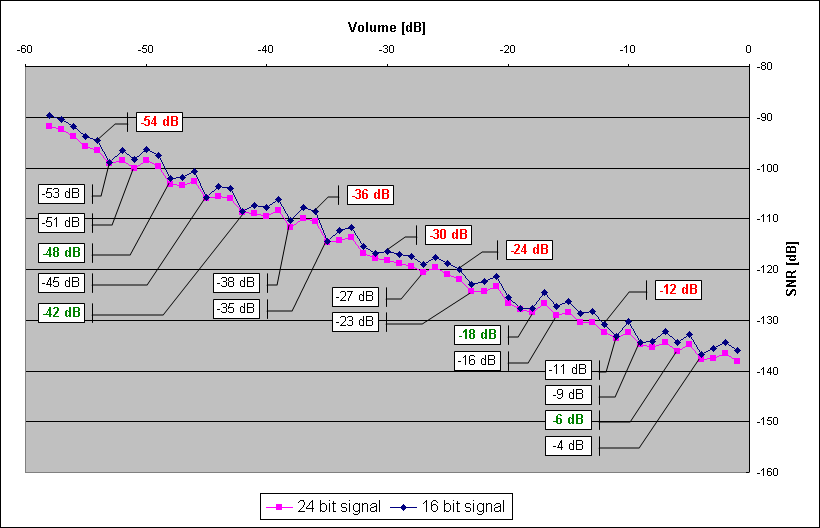
The signal processing pipeline is 24 bit wide, and the test signal was quantized at either 24 or 16 bits. The small difference in noise between 24 bit and 16 bit signals stems from the fact that the signals are compared to the quantized versions (as in the real life, you only have quantized signal as reference, not the original). So the graph shows that the 24 bit signal is less damaged from scaling than 16 bit signal, not that 24-bit signal has bigger SNR by itself.
Another interesting thing is the numbers in boxes. Below the plot there is a list of local minimas - a settings that cause less noise than the ones around them. Above the plot, there is a list of integer multiples of 6, which are noisier than their neighbours. So how to use it? Just stick with the numbers below the line and you'll be getting (ever so slightly) less scaling noise.
contents: pictures and text
hw requirements: none
os: os independent
Kindle Color

No, unfortunately, this utility will not make your Kindle display colors. It is meant for people who dropped their Kindle or otherwise accidentally damaged the display. Although Amazon is mostly willing to replace broken devices for free, some users may be stuck with their broken Kindle.
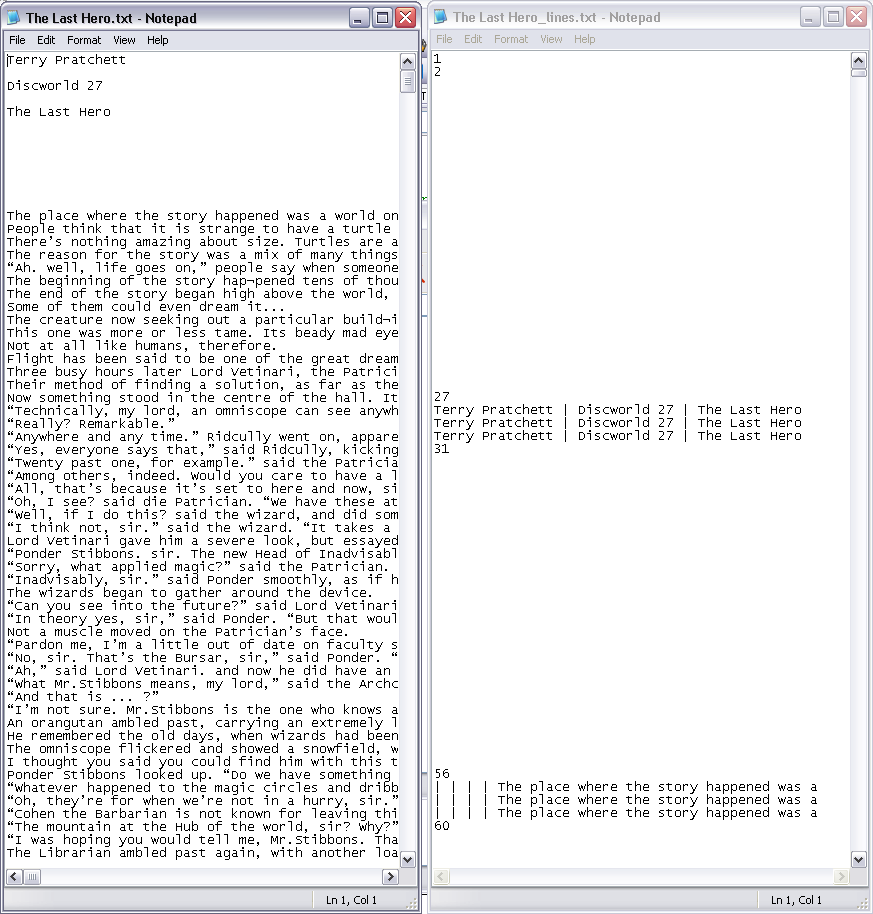
This little utility splits text files in order to only utilize a small portion of the display in order to make them readable on broken devices as well. It transforms plain text to "sparse" text so that there are only blanks on the broken part of the display.
{kind=link}
There are some more peculiarities with Kindle. It can only turn the whole pages of text at a time, but when going back and forth, it sometimes shifts the page one line of text up or down. That's why there are line numbers and the line of text itself is repeated several times (in order not to fall out of the working part of the display).
I use this on my Kindle 3, but it should work on pretty much any Kindle (there may be need to change number of lines that fit one page; the line numbers can aid in doing that). The only limitation is that the text needs to be stored in 8-bit encoding (no unicode at the moment, although it would be trivial to add the support for it). Also, I use this on Kinlde that can display only one line of text at a time, someone with larger part of the display still working may want to display more than a single line - just let me know.
contents: source code, win32 binaries
hw requirements: none
os: os independent
HDD LED
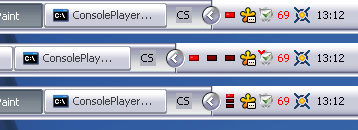
Tiny utility, displaying hard-drive LED in tray icon, suited for people who have their computer under the table and have very quiet hard-drives, like i do. It also comes in handy when working over remote desktop / VNC. It has no other GUI, so it's memory footprint is feeble and it's CPU load is close to zero (that also depends on update speed). It can display more than a single device, either in a single icon (top), in more icons (middle), or in icon split to more sub-icons (bottom).
The source code is very simple, it should be rather easy to implement more features or tailor it to suit your individual needs. And what's best, it only uses pure windows api, no low-level hacks, so there is no chance of it causing any problems in your computer. Works on both x86 and x64.
contents: source code and binaries
hw requirements: none
os: windows 2000 or better
MPlayer reposition utility
This is small commandline utility i wrote to command arround MPlayer window. I have two 19" displays, one next to the other (combined diagonal 32.5") ... this is good for watching widescreen movies (each display have ratio 4:3, so "combined" ratio is 2.666:1 (or 8:3), which is strikingly close to 2.35:1 (for example the Sunshine movie comes in this format)). While this is neat, watching movies with lower aspect ratios can be frustrating because of the monitor edges in the middle, while area actually not much larger than of a single display is being used (so it's better to watch on a single display, perhaps).
While switching display configuration can be done from NVidia Control Panel, it can be tiresome, and it makes monitors switch off and back on immediately, probably shortening their lives (fluorescent lights, used as backlight in most today's LCD's do not like to be switched off and on).
This simple utility grabs MPlayer window, moves it to desired location, and creates black windows all arround, so it looks like in fullscreen mode. This also has some advantages, it is possible to align MPlayer to side, so the dividing line is no longer in the middle of the picure, but either on the edge for 4:3, in one third for 16:10, or almost in the centre for 2.35:1. See the pictures below for the idea of what each configuration looks like:

Sunshine (2.35:1), centered

Final Fantasy: The Spirits Within (1.85:1), centered + left align

Evangelion Rebuilt 1.0 - You Are (Not) Alone (1.5:1), centered + left align

Eraserhead (1.33:1), left
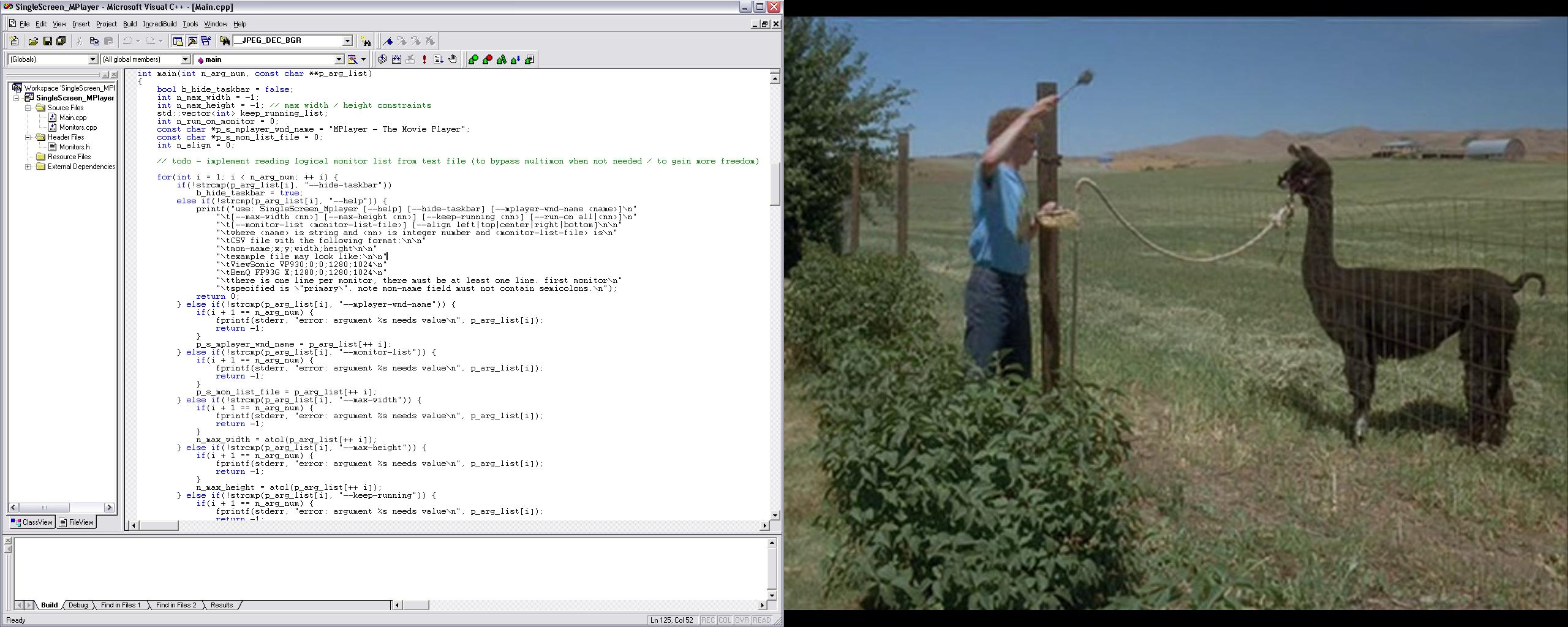
Napoleon Dynamite (1.33:1), right + left intact
More configurations are possible, more than two monitors are possible as well. Some of them are acheivable using certain display configurations, some are not.
This works as follows: you run MPlayer in a window and launch this utility with proper commandline. That's it. The utility automatically quits as soon as MPlayer finishes.
contents: source code and win32 executable
hw requirements: multiple displays
os: win32 only
Image-to-header utility 2.0
Image to header is small command-line utility, created for purpose of converting images to source code form. It reads image in jpeg / tga format, may do some image processing (currently only grayscale conversion is available) and stores the image as a C++ class.
This uses somewhat more ealborate (lossy) compression scheme, than it's predecessor. It works in YCbCr color space (or grayscale) and allows chromacity planes subsampling, similar to JPEG. It also allows storing chromacity with less than 8 bits per pixel (kind of "quantisation"). Then, there's the prediction step, using one of up / left / average / paeth predictors, not unlike PNG does. Finally, there's RLE step and a Huffman coder. Output is stored as BASE64 C++ string.
While this may seem quite complicated, decoding takes 150 lines of neat plain C++ (without crazy macros, obfuscation or whatever someone may think of to make code shorter). Compression ratios about 5:1 can be achieved with RGB images (photographs) without noticeable visual artifacts (this is lossy, remember?). It's not very impressive, but sufficient (given simplicity of decompressor code). Also note, the final BASE64 step expands data in 3:4 ratio (without it, we could achieve ratios arround 6.666:1 ... which is impressive neither ;)).
The only aim is to avoid including some additional files for projects that just need to display small logo, etc ...
contents: source code and win32 executable
hw requirements: none
os: win32, should be compilable under linux as well
3ds-to-header utility
3ds to header is small command-line utility created for purpose of converting 3ds files to source code form. It reads 3ds file and stores it as C++ source code. It stores object definitions, materials, lights and cameras, including animation tracks. You can see included test.h which contains exported code for test.3ds to see how the code looks like.
The only aim is to avoid including some additional files for projects that just need to display simple model, etc ...
contents: source code and win32 executable
hw requirements: none
os: win32, should be compilable under linux as well
GPGPU with ÜberLame
Article on GPGPU with UberLame framework.
contents: article and demo
hw requirements: OpenGL 2.0 capable graphics card
os: win32, linux makefile missing
Generating random directions with uniform distribution
Article on generating random direction vectors with uniform distribution. Handy for particle systems.
contents: pictures and text
hw requirements: none
os: os independent
Qt 4.3.4 patch for MSVC 6.0
I was forced to build Qt libraries under my beloved MSVC 6.0. Unfortunately, it's not really simple because of somewhat obscure syntax. Qt is using this:
template <typename Foo>
class Bar {
...
};
But my MSVC 6.0 only accepts this:
template <class Foo>
class Bar {
...
};
I'm a little bit confused, my C++ book from Bjarne Strostrup says the latter is correct, but obviously Qt guys must be able to build it somewhere ... Anyway, this patch fixes all occurences of template <typename ...> so it's possible to build Qt with MSVC 6.0 as well. Inside there's a short tutorial descriptiong use of this patch.
contents: source code, win32 executable and short description on how to use
hw requirements: none
os: win32 / linux (msvc / g++)
Skybox generator
A little skybox generator utilizing several new unique approaches. Despite it's name it's not finished, there's still stuff to do ... i just think i'm not going to.
contents: source code, win32 executable and czech documentation
hw requirements: OpenGL, GL_ARB_texture_cubemap
os: win32 / linux (msvc / g++)
Concrete Jungle: making of
This is a little article (more pictures than text, actually) about making the Concrete Jungle, my current (and hopefuly everlasting) loudspeaker set.
contents: pictures and text
hw requirements: none
os: os independent
MPlayer 1.0rc2 win32 build
Our nice linux MPlayer, built for win32. Built with runtime cpu detection. You can get MPlayer at MPlayer official site, but they didn't offer win32 build of newer version at the time so i managed to build it myself ... and as it was one hellable job, getting all the necessary libs and waiting whole day for turtle-slow autoconf, i thought it might be useful to other folks as well. You can get changelist at the website, but for me the reason to get the new version was the old version refused to play big endian AAC streams.
contents: win32 executable, binaries
hw requirements: none
os: win32
Gallery maker v1.11
Very simple utility for automated creation of HTML / XHTML galleries. It downsizes images, generates thumbnails, can apply contrast and / or color correction.
Changes from previous version 1.0 include: more senseful error messages, input value error checking, the 'Break operation' button and 'Cancel' buttons on all error messages. Future plans? Maybe some more serious image processing such as noise reduction, sepia filtering, etc. Maybe rewrite the code so it's less messy :). Maybe also support another gallery format, using div as image container instead of table, image comments, neat javascript windows for picture viewing, displaying image comment and some other useful stuff.
contents: source code and win32 executable
hw requirements: none
os: win32
Glut game in 16kB
A little glut game, demonstrating use of procedural texturing, simple spline to mesh conversion and OpenGL selection. See glut game screeenshot. I made it for one of my friends who needed this for her lecture so she could screen it to the rest of the class. Partialy made for amusement, don't take it too seriously, the aim was maximal compatibility, not graphical perfection.
{kind=link}
I've toyed with this for some time, i've added anisotropic filtering and optimised it all a little bit so now the executable size is 16kB. It's by no means impressive, i guess such an app could be stuffed into 8kB or maybe even less. There is a lot of memory taken by extension strings in the extension handler and for example the std::vector (Hewlett-Packard implementation in MSVC) isn't very small as well, even when optimizing for size:
| code size [B] | function name |
|---|---|
| 160 | std::vector<TStand>::reserve |
| 17 | std::vector<TStand>::push_back |
| 48 | std::vector<TStand>::erase |
| 545 | std::vector<TStand>::insert |
| 3121 | TGLState::Update |
| 1596 | CGLExtensionHandler::n_GetGL20FuncPointers |
But considering the fact it's using the huge ÜberLame C++ ballast, 16kB is not so bad after all. Maybe once i'm bored again i'll try to build it from scratch using C only to see where i can get.
ÜberLame framework r17 is necessary to compile this, the newest version can be found in projects section.
contents: source code and win32 executable
hw requirements: OpenGL capable graphics card
os: linux / win32
Honneypie recipe
This is a little tutorial on how to make traditional czech dessert - honneypie.
contents: pictures and text
hw requirements: none
os: os independent
Convex madness
Tutorial series about convex madness. Convex madness is passion, exhibited by most individuals interested in computer graphics. All you need is convex happiness.
contents: tutorials with included source code and win32 executable
hw requirements: OpenGL capable graphics card
os: linux / win32
C2Htm
Very simple MFC app i use for coloring code snippets i want to insert to html.
contents: source code and win32 executable
hw requirements: none
os: win32
Image-to-header utility
Image to header is small command-line utility created for purpose of converting images to source code form. It reads image in jpeg / tga format, may do some image processing (currently only grayscale conversion available) and store the image as C source code. Can use RLE compression and even include decompressing routine into the header.
The only aim is to avoid including some additional files for projects that just need to display small logo, etc ...
contents: source code and win32 executable
hw requirements: none
os: win32, should be compilable under linux as well
Hex-lattice screensaver
Very simple OpenGL screensaver, displaying lattice of rising and falling hexadecimal rods. Features simple normalmapping and depth of field. (postprocessing shader with adaptive sampling) Multiple monitor support. (can be very exhaustive for graphics memory and fillrate) See hex-lattice screenshot or the other hex-lattice screenshot.
contents: source code and win32 executable
hw requirements: graphics card with glslang support (GF 5xxx+)
os: win32